
목록전체 글 (245)
Joonas' Note
 Android Studio 깨끗하게 정리하기
Android Studio 깨끗하게 정리하기
참고한 원문 Put your Android Studio on a diet How to make a deep clean of your Android Studio & Gradle junk files to fix up the mess. engineering.backmarket.com aar 내에 있는 클래스를 자꾸 인덱싱을 못 하길래 검색하다가 찾은 방법인데, 생각보다 유용해서 블로그로 옮긴다. 참고로 위 문제는 해결 못 했다. 🤔 요약 1) "Build -> Clean Project" 로 먼저 빌드된 파일들 삭제 2) "File -> Invalidate Chaces / Restart" 로 캐시 제거 (안드로이드 스튜디오가 다시 시작되면 gradle을 다시 읽고 처리하는 데 일단은 무시) 3) .gradle ..
함수의 실행 속도를 측정하는 코드이다. 다음과 같이 함수들을 미리 선언해둔다. import time def measure(func): """ Returns milliseconds how much time takes to run given func """ start = time.time() func() end = time.time() diff = end - start return diff * 1000 def bench(func, k: int = 1, params: list = [{}], title: str = ''): pcnt = len(params) pstr = f" x {pcnt} params" if pcnt > 1 else '' print(f"[run x {k}{pstr}] {title}") t = ..
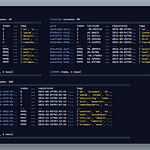 [파이썬 패키지] 설치 없이 가벼운 데이터베이스 (json-as-db; JAD)
[파이썬 패키지] 설치 없이 가벼운 데이터베이스 (json-as-db; JAD)
최근에 회사에서 간단하게 파이썬으로 스크립트를 작성하다가 데이터베이스를 사용해야할 일이 있었다. 간단한 목적이라 단순한 연산들만 있으면 되는데, 불필요하게 거대한 사이즈의 패키지들(SQLAlchemy, PyMongo 등)을 설치해야하는 게 불편했다. 왜냐하면 경험상 이것들은 초기에 별도로 설정해야하는 작업이 굉장히 많기 때문이다. 그래서 in-memory 여도 좋으니 간단한 설정으로 마치 json 객체처럼 사용할 수 있는 패키지가 있는 지 찾아보았는데, 이 당시에는 찾지 못했다. 개발을 꽤 마친 이후에 tinyDB 라는 아주 비슷한 동작의 패키지를 발견했다. (지금와서 보면 dict 호환성 측면에서 아주 미묘하게 다르다.) 그럼 패키지를 사용하지 않고 built-in 패키지인 json 으로 커버하자니, ..
삼바 연동은 정상적으로 되고 있었고, 서버쪽 설정도 변경이 없었다. 특히 다른 IP와 PC에서는 되는 데 한 컴퓨터에서만 유독 계속 안되고 있었다. 인터넷에 나오는 방법들은 전부 해봤는데 모두 안됐고, CMD 로 실행하니까 그나마 오류 코드라도 알 수 있었다. CMD> net use \\ /user:joona 시스템 오류 1219이(가) 생겼습니다. 동일한 사용자가 둘 이상의 사용자 이름으로 서버 또는 공유 리소스에 다중 연결할 수 없습니다. 서버나 공유 리소스에 대한 이 전 연결을 모두 끊고 다시 시도하십시오. 해결 방법은 CMD를 관리자 권한으로 실행하고, 아래 커맨드를 순서대로 입력하면 된다. sc stop netlogon sc stop sessionenv sc stop lanmanworkstati..
 [강화학습 일지] DQN Tutorial 살펴보기
[강화학습 일지] DQN Tutorial 살펴보기
PyTorch 공식 문서에서 강화학습(Reinforcement Learning)의 한 예시로 DQN 튜토리얼이 있어서 살펴보기로 했다. 시간이 많이 지나서 깨달은 사실은, 한글 문서와 영어 문서의 내용과 도메인이 다르다는 것이었다. 한글 문서: https://tutorials.pytorch.kr/intermediate/reinforcement_q_learning.html 영어 문서: https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html 한글 문서의 경우에는 Cart-Pole-v0 을 기준으로 작성된 예전 내용이라서, Cart-Pole-v1로 그대로 옮기면 학습도 잘 안되고 동작 방식에도 큰 차이가 있었다. 참고로 한글 문서는 1..
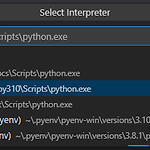 VSCode에서 Python 버전 변경하기
VSCode에서 Python 버전 변경하기
VSCode에서 파이썬 프로젝트를 작업하다보면, 분명 pip로 설치한 패키지인데 import 하는 코드에 밑줄이 있는 경우가 있다. 이럴 때 커서를 가져다대서 이유를 확인해보면 Import "" could not be resolved 인 경우가 많은데, 어쨌건 해당 모듈을 찾을 수 없다는 뜻이다. VSCode를 열었을 때, 같은 디렉토리에 가상 환경이 있다면 알아서 잡아주지만, 그렇지 못한 경우도 있다. 가상환경이 활성화 된 경우에는 VSCode 오른쪽 하단에 아래와 같이 표시된다. 위와 같은 창을 못 봤다면, 직접 고를 수 있다. "상단 메뉴 > View > Command Palette" 또는 "Ctrl+Shift+P" 로 명령어 실행 창을 띄워서 "Python: Select Interpreter" 를..
 아나콘다(Anaconda) 없이 가상환경 세팅하기
아나콘다(Anaconda) 없이 가상환경 세팅하기
개요 아나콘다(Anaconda)는 파이썬의 버전과 패키지들의 버전을 쉽게 관리할 수 있게 해주는 강력한 솔루션이다. 하지만 200명 이상 규모의 회사에서는 개인용 버전인 Anaconda Distribution을 사용할 수 없다고 한다. 그리고 어떤 패키지들은 아나콘다에서 추적하지 못할 수도 있다. 파이썬의 버전과 각 프로젝트에 맞는 가상환경을 쉽게 구축하고 관리하는 것을 아나콘다의 기능이라고 보고, 이번 글에서는 아나콘다를 사용하지 않고 classic하게 관리하는 환경을 구축한다. 먼저, 크게 세 가지로 나눠서 접근해보자. 파이썬 버전 관리 패키지 관리 가상 환경 관리 파이썬 버전 관리 파이썬은 특정 패키지들이 버전을 지원하지 않으면 버전을 내려야하는 경우들이 종종 있다. 예를 들면 Python 3.7 ..
패키지를 설치하다보면, 모종의 이유로 wheel을 직접 다운로드하는 경우가 있다. wheel을 직접 다운로드 하려고하면, 설치하려는 환경에 따라서 whl 파일이 엄청나게 많은데, 그럴 때마다 운영체제, 비트, python 버전 등을 전부 한번씩 확인하게 된다. 잘못된 whl 파일로 설치하려고 하면 아래와 같은 에러를 만나서 무척 피곤해진다. ~~.whl is not a supported wheel on this platform. 2018년에 TensorFlow의 GitHub repository에서 동일한 질문이 있었고 https://github.com/tensorflow/tensorflow/issues/9722 , 아래와 같이 엄청 간단한 커맨드로 쉽게 확인할 수 있었다. Linux/Mac $ pytho..