
Joonas' Note
[딥러닝 일지] 과적합 문제, 그리고 배치 전략 (교차 검증) 본문
이전 글 - [딥러닝 일지] 이진 분류를 위한 CNN 모델 작성 (개 vs 고양이)
[딥러닝 일지] 이진 분류를 위한 CNN 모델 작성 (개 vs 고양이)
이전 글 : [딥러닝 기록] 시작하기 - 개 vs 고양이 분류 [딥러닝 기록] 시작하기 - 개 vs 고양이 분류 딥러닝을 공부하면서, 헷갈리는 내용이나 앞으로 알아봐야 할 내용들을 블로그에 정리하기로
blog.joonas.io
정확도를 높이고 싶다!!
개와 고양이를 더 잘 구분하고 싶었다!! 나의 욕망은 무리한 삽질의 반복만 낳았다.
이전에 작성했던 MLP 모델의 네트워크에서 Convolution의 커널(kernel) 크기도 바꿔보고, stride 크기도 바꿔보고, 뒤 쪽 classifier에서 drop out도 해보고.. 이것 저것 해보았지만 결과는 계속 같았다.
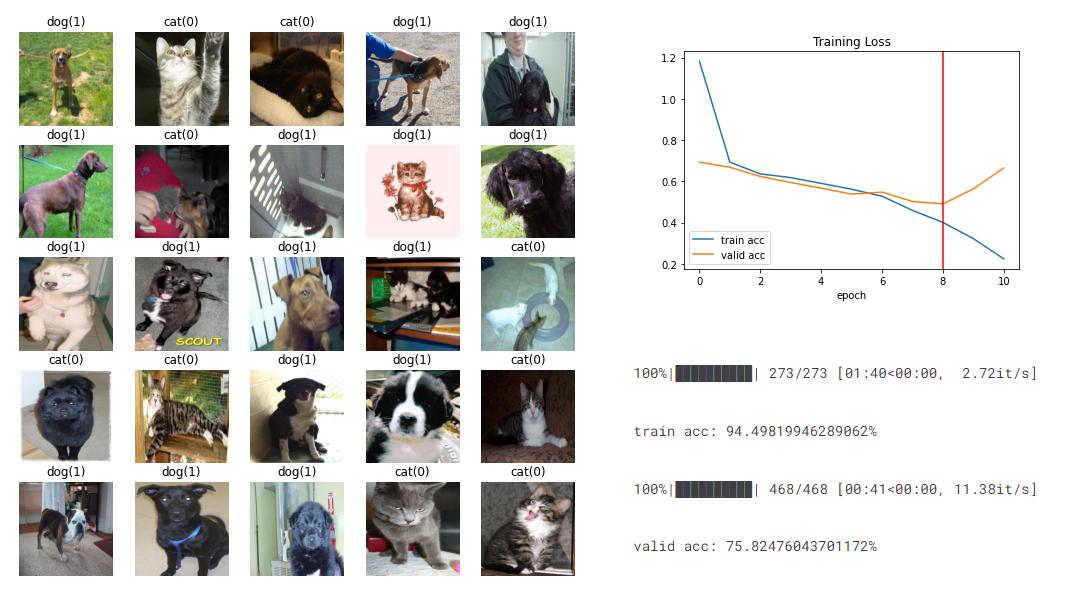
모델을 이렇게 저렇게 수정해봐도 결과는 계속 같았다.
그리고 깨달았다. train set의 데이터만 학습하고 있어서 모델이 과적합이 된 것이다.
그런데 이해가 되지 않는다. 분포가 비슷한 train.zip의 이미지들을 적당히 나눠서 train과 test로 썼기 때문에 거의 같은 데이터일텐데 이렇게 곧장 갈라질 정도로 데이터가 치우져져 있나?

train dataset에 있는 이미지는 약 17500장 정도이고, test dataset의 이미지는 약 7500장이다.
train dataset의 배치 크기는 64로, 한 번의 epoch마다 64개의 이미지씩 273번을 학습한다.
배치 크기가 문제일까?
배치 크기가 너무 크면, 한 번에 학습하는 이미지가 너무 많기 때문에 과적합이 일어날 수 있다. 하지만 그렇게 많이 GPU에 올릴 만큼 자원이 있지 않았기 때문에, 영향을 미칠 정도로 중요한 문제가 아니다.
교차 검증
학습에 주어지는 train set은 epoch마다 반복되어 사용된다. 즉, 다음 epoch가 돌아오면 순서만 다르지 결국 같은 데이터(이미지)를 보고 특징을 추측하고 있는 것이다.

교차 검증은 학습 데이터의 일부를 학습에서 제외시킨다. 제외한 부분은 아까우니까 정확도를 검증하는 용도로 쓴다. (Valid set)
그런데 생각해보면 Train Dataset의 크기만 작아졌지 결국 똑같은 구조 아닌가?
K-Fold 교차 검증

그러니까 학습에서 제외되는 Valid set은 epoch마다 바뀌어야한다. (과적합을 막는 것이 목적이므로)
K-Fold는 한 사이클의 학습에서 사용할 K-1개의 학습 데이터와 1개의 검증 데이터로 나누는 전략이다.
위 그림은 Train Dataset을 4개로 쪼깨는 K=4 인 예시이다.
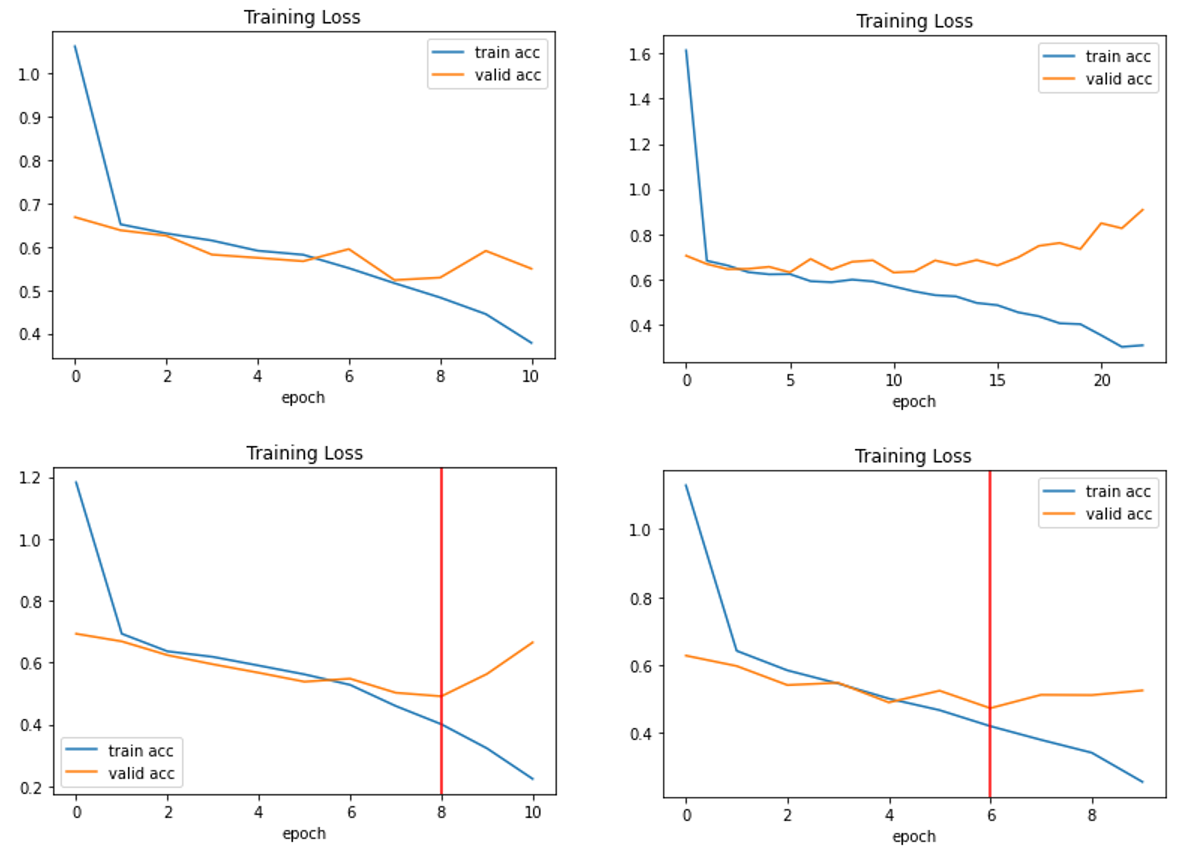
모델 레이어, 손실 함수, 최적화 함수 등의 다른 변경 없이 K-Fold 교차 검증만 적용했는데도 아래처럼 학습되었다.
여기까지가 Version 24 이다.
Dogs vs. Cats Classification
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
쪼개진 것들(fold)마다 어떻게 학습되고 있나 궁금해서 그래프를 찍어봤다.
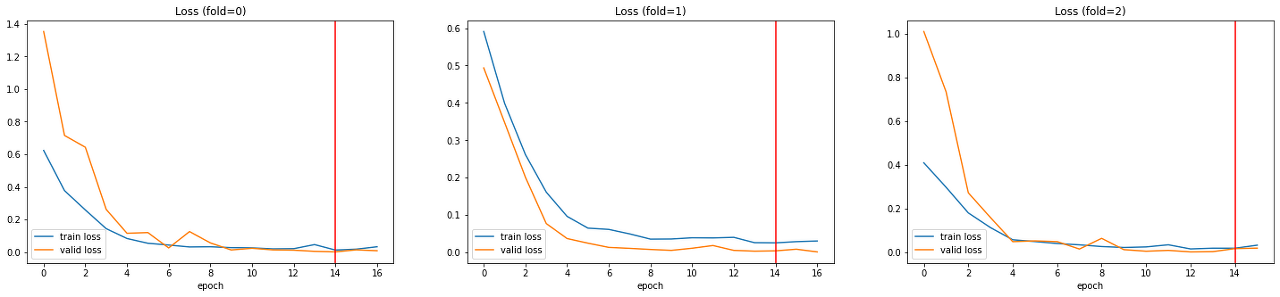
물론, 각 fold를 진행할 때의 loss를 그린 것이므로 독립적인 결과는 아니다.
fold 개수는 얼마가 좋을까
지금 학습 데이터는 약 17500장이다. 각 학습 세트를 3개로 쪼갠다면 약 11600장으로 학습을 할 것이고, 4개로 쪼갠다면 약 13200장으로 학습할 것이다. 이건 가지고 있는 데이터의 크기를 보고 결정해야할 부분인 것 같다.

이번에 여러 케이스로 실험을 해보면서 kaggle에서 기본으로 제공하는 GPU 사용 시간을 거의 다 썼다.
저장해놓고 자러 갔기 때문에, 시간을 낭비한 적도 많다.
그래서 다음 글은 조기 종료(early stop)이다.

'AI > 딥러닝' 카테고리의 다른 글
| [딥러닝 일지] 이미지 가지고 놀기 (변환하기) (8) | 2022.03.24 |
|---|---|
| [딥러닝 일지] 다른 모델도 써보기 (Transfer Learning) (0) | 2022.03.13 |
| [딥러닝 일지] 학습 조기 종료 (Early Stop) (0) | 2022.03.13 |
| [딥러닝 일지] 이진 분류를 위한 CNN 모델 작성 (개 vs 고양이) (0) | 2022.03.09 |
| [딥러닝 일지] 시작하기 - 개 vs 고양이 분류 (0) | 2022.03.07 |



