
Joonas' Note
[딥러닝 일지] VAE; Variational Auto Encoder 본문
이전 글 - [딥러닝 일지] Auto Encoder (with MNIST)
AE와 다른 점

인코더로 매핑한 잠재 공간의 어떤 포인트들이 정규 분포의 형태로 만들어진다는 점이다.
다시 말해, 디코더로 만들어지는 비슷한 샘플 이미지들은 비슷한 잠재 공간으로부터 만들어진다는 의미이다.
잠재 공간을 살펴보면, 각 레이블별로 AE에 비해 더 뭉쳐있을 것이다.

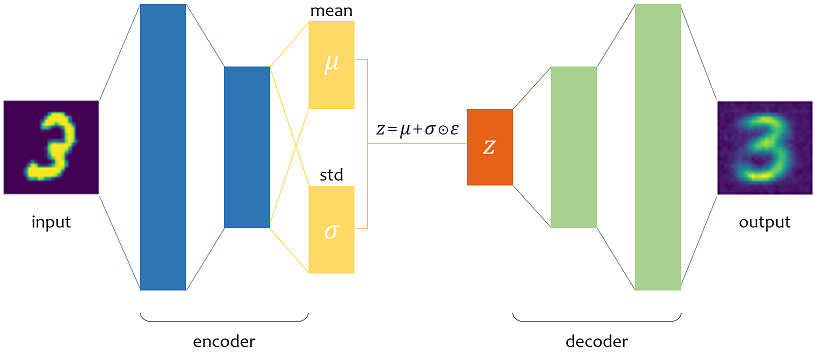
이제 encoder는 각 차원별로 확률 분포를 구하기 위해 평균(mean)과 표준편차(std)를 학습한다. 특징들의 평균과 분산을 계산하는 것이다.
z가 되는 수식에서 엡실론 \( \varepsilon \) 은 표준 정규 분포 \( {\displaystyle \mathrm {N} (0,1)} \) 를 따르는 적당한 난수이다.
코드에서 바뀌는 부분은 이렇다.
class VAE(nn.Module):
def __init__(self, z_dim=2):
super().__init__()
self.encoder = nn.Sequential(
# ...
nn.Flatten(),
)
self.fc_mu = nn.Linear(64 * 7 * 7, z_dim)
self.fc_var = nn.Linear(64 * 7 * 7, z_dim)
self.decoder = nn.Sequential(
nn.Linear(z_dim, 64 * 7 * 7),
# ...
nn.Tanh(),
)
def forward(self, x):
x = self.encoder(x)
self.mu = self.fc_mu(x) # mean
self.log_var = self.fc_var(x) # log(std^2)
std = torch.exp(self.log_var / 2) # std = exp(log(std)) = exp(2*log(std)/2) = exp(log(std^2)/2)
eps = torch.randn_like(std)
z = eps * std + self.mu
x = self.decoder(z)
return x
Loss function
손실을 계산하는 부분도 바뀐다. 두 확률분포 간의 차이를 계산해야하기 때문에 KL-Divergence를 사용한다.
자세한 내용은 https://darkprogrammer.tistory.com/3 에서 읽으면 좋다.
아래 첨부할 노트북에서 확인할 수 있는 수식은 아래와 같다.
kld_loss = -0.5 * torch.sum(1 + log_var - mu ** 2 - log_var.exp(), dim=1)기존의 AE과 같이, 만들어진 출력값과 정답 간의 손실과 kld loss를 단순하게 더하면 gradient 값이 상당히 커서 학습이 잘 안될 수 있다.
여기에 별도로 weight 상수를 곱해서, KL-Divergence의 손실은 조금만 계산되도록 했다.
kl_weight = 1e-3
kld_loss = (kld_loss * kl_weight).to(device)
결과

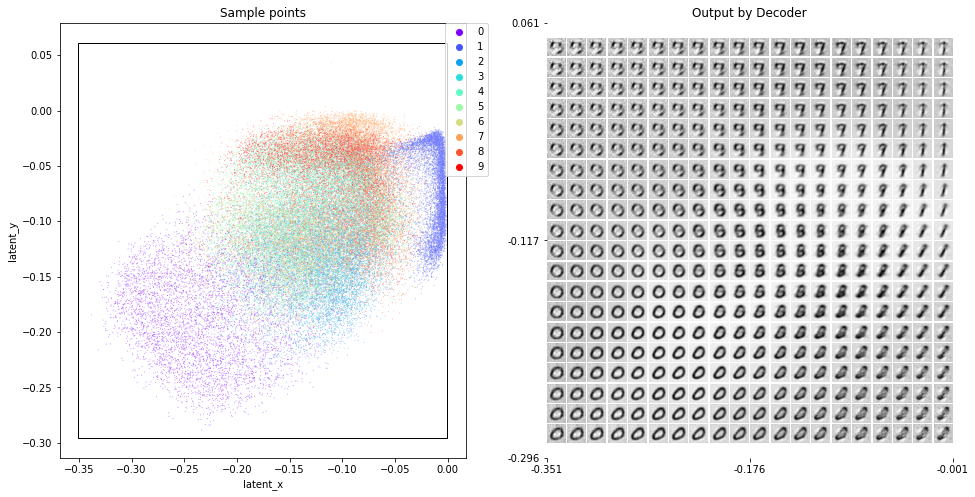
이전글과 동일하게 잠재 벡터의 크기를 2차원으로 놓고 학습시켰다.
솔직하게 결과가 더 나아진지는 모르겠는데, 각 레이블의 클러스터마다 조금씩 구분이 생긴 것 같다. (서로 뭉쳐서 생긴 간격)

비교를 위해 Auto Encoder의 결과 중 하나를 가져왔다.
물론 Auto Encoder도 분포가 잘 되는 케이스가 있지만 그건 운으로 만들어진 것 같고, VAE는 의도적으로 정규 분포가 되도록 유도하므로 이런 차이가 생기는 것으로 보인다.
노트북
VAE의 실행 스크립트와 결과 이미지는 아래의 캐글 노트북에서 확인할 수 있다.
https://www.kaggle.com/code/joonasyoon/mnist-vae-variational-auto-encoder-visualization
MNIST VAE(Variational Auto Encoder) Visualization
Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
www.kaggle.com
'AI > 딥러닝' 카테고리의 다른 글
| [딥러닝 일지] WGAN (Wasserstein GAN) (0) | 2022.06.11 |
|---|---|
| [딥러닝 일지] PyTorch로 DCGAN 훈련해보기 (4) | 2022.06.08 |
| [딥러닝 일지] Auto Encoder (with MNIST) (0) | 2022.06.03 |
| [PyTorch] RuntimeError: DataLoader worker is killed by signal: Bus error. (0) | 2022.05.30 |
| [PyTorch] AssertionError: Torch not compiled with CUDA enabled (0) | 2022.05.30 |


