
목록전체 글 (255)
Joonas' Note
 [딥러닝 일지] VAE; Variational Auto Encoder
[딥러닝 일지] VAE; Variational Auto Encoder
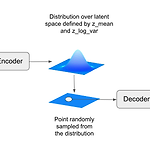
이전 글 - [딥러닝 일지] Auto Encoder (with MNIST) AE와 다른 점 인코더로 매핑한 잠재 공간의 어떤 포인트들이 정규 분포의 형태로 만들어진다는 점이다. 다시 말해, 디코더로 만들어지는 비슷한 샘플 이미지들은 비슷한 잠재 공간으로부터 만들어진다는 의미이다. 잠재 공간을 살펴보면, 각 레이블별로 AE에 비해 더 뭉쳐있을 것이다. 이제 encoder는 각 차원별로 확률 분포를 구하기 위해 평균(mean)과 표준편차(std)를 학습한다. 특징들의 평균과 분산을 계산하는 것이다. z가 되는 수식에서 엡실론 ε 은 표준 정규 분포 N(0,1) 를 따르는 적당한 난수이다. 코드에서 바뀌는 부분은 이렇다. ..
 [딥러닝 일지] Auto Encoder (with MNIST)
[딥러닝 일지] Auto Encoder (with MNIST)
이전 글 - [딥러닝 일지] MNIST Competition 생성 모델 이번에는 MNIST 데이터셋으로 0~9 사이의 숫자를 주면 28x28 크기의 숫자 이미지를 만들어내는 생성 모델을 연습했다. 그 중에서도, 가장 기초적인 형태의 오토 인코더(Auto Encoder) 모델이다. 입력 이미지를 잠재 공간(Latent space)의 어떤 형태로 만드는 Encoder 부분과, 잠재 공간의 값을 다시 재구성하는 Decoder 부분으로 이루어진다. 여기서 잠재 공간의 차원은 2개, 10개 등 상관없고 당연하겠지만 고차원일수록 많은 표현들을 내포할 수 있으므로 좋다. 레이어를 분리해서 학습을 진행하는 경우도 있고 하나로 합쳐서 학습해도 되는데, 중간값을 확인할 수 있도록 분리해서 진행했다. encoded = En..
오류 RuntimeError: DataLoader worker is killed by signal: Bus error. It is possible that dataloader's workers are out of shared memory. Please try to raise your shared memory limit. DataLoader를 사용하는 코드에서 worker를 너무 많이 사용해서 공유 메모리가 부족해진 문제이다. 공유 메모리의 용량을 늘리면 당연히 해결되겠지만, 그럴 수 없는 경우도 있다. 해결 방법 Linux 계열의 경우에는 df -h 명령어로 메모리 사용 현황을 확인할 수 있다. Filesystem Size Used Avail Use% Mounted on overlay 1.8T 202G ..
집에 있는 데스크탑에 주피터를 새로 설치했다. 아나콘다는 따로 사용하지 않다보니까 별도로 가상환경을 준비했다. 간단하게 모델을 학습하려고 이전에 잘 동작했던 노트북 파일을 조금 수정해서 실행했는데, 아래와 같은 에러가 났다. File C:\Python38\lib\site-packages\torch\cuda\__init__.py:210, in _lazy_init() 206 raise RuntimeError( 207 "Cannot re-initialize CUDA in forked subprocess. To use CUDA with " 208 "multiprocessing, you must use the 'spawn' start method") 209 if not hasattr(torch._C, '_cuda..
 [ML] 사이킷런(scikit-learn) 클러스터링 비교
[ML] 사이킷런(scikit-learn) 클러스터링 비교
시작하기 앞서 sklearn에서는 다양하고 많은 클러스터링 module들을 제공한다. 공식 문서에서도 여러 데이터 분포에 대해서 비교한 것이 있길래 직접 해보고자 했다. sklearn에서는 make_blob과 같이 데이터를 생성해주는 함수가 있다. 범위와 분포값을 설정해서 임의로 만들 수 있지만, 이것은 사용하지 않기로했다. 데이터 만들기 현실에서는 이렇게 고른 분포가 나오기 힘들다고 생각했고, 2차원 평면 상에서 직접 데이터를 만들기로 했다. GUI tool to create points for clustering www.joonas.io 캔버스와 마우스 이벤트를 이용해서 그림판처럼 데이터를 그릴 수 있게 했고, csv로 (x 좌표, y좌표, 색상 번호)를 추출할 수 있도록 간단하게 만들었다. 데이터셋..
 [코딩으로 풀어보기] 문제적 남자 4화 - (9, 9, 9, 9, 9, 9)으로 100 만들기
[코딩으로 풀어보기] 문제적 남자 4화 - (9, 9, 9, 9, 9, 9)으로 100 만들기
문제 이번 문제는 문제적남자 4화에 나온 뇌풀기문제이다. 6개의 9를 사용해서 100을 만드는 수식을 찾는 문제인데, DFS로 모든 경우의 수를 탐색하면 되는 전형적인 문제로 보인다. 숫자들 사이에 수식을 끼워 모든 경우의 수를 만들어보고, 파이썬의 eval 함수로 계산한 결과가 100 이 되는 경우만 세어보면 될 것 같다. 9와 사칙연산만 사용하기 6개의 9 사이마다 사칙연산을 끼워넣어서 100이 만들어지는 경우를 찾아본다. 4개의 연산자를 5개의 공간에 끼워넣으므로 경우의 수는 45=1024 가지밖에 되지 않는다. 정답은 12개로 생각보다 많은데, 이건 순열이 달라서 세어진 것이고 조합으로 보면 단 하나이다. (정답 아래에 적음) 정답 9+9+9/9+9*9 = 100.0 9+9+9*9+9..
 Content-based File Format Detection (파일 확장자 예측)
Content-based File Format Detection (파일 확장자 예측)
Dataset https://www.kaggle.com/datasets/joonasyoon/file-format-detection Programming Laungages and File Format Detection can you know what file format is? and written in which language? www.kaggle.com Code https://www.kaggle.com/code/joonasyoon/ml-content-based-file-format-detection [ML] 💾 Content-based File Format Detection 📃 Explore and run machine learning code with Kaggle Notebooks | Using d..
압축 파일을 압축 해제하려고 아래처럼 unzip을 실행했는데 에러가 났다. $ unzip dataset.zip -d data Archive: dataset.zip End-of-central-directory signature not found. Either this file is not a zipfile, or it constitutes one disk of a multi-part archive. In the latter case the central directory and zipfile comment will be found on the last disk(s) of this archive. unzip: cannot find zipfile directory in one of dataset.zip or ..