
Joonas' Note
[부동산 가격 예측] LightGBM에서 DNN Regression으로 본문
이번 글에서 사용되는 데이터셋은 Kaggle의 한 Competition인 house-prices-advanced-regression-techniques이다.
개와 고양이 분류 이후로, 회귀(Regression) 모델을 연습하기 위해서 적당한 주제를 잡던 중에 먼저 ML 모델로 데이터 전처리(preprocessing)부터 연습하기로 했다.
Regression 모델로 LinearRegression, Ridge, Lasso 이렇게 3개로 학습하면서 튜닝해봤는데, LightGBM이 가장 loss가 낮아서 그걸로 제출했더니 가장 순위가 좋았다. 그래도 RMSE 0.17812(상위 77%)로 매우 낮은 예측을 보였다.
https://www.kaggle.com/code/joonasyoon/ml-practice-on-regression?scriptVersionId=93141794
전처리에 매우 민감하게 반응하는 데이터셋이었다.
정규 분포로 만들고 Ridge로 학습했을 때 RMSE가 0.49551였는데, Outlier를 제거했더니 그 절반인 0.28777으로 줄었다.
여기서 모델을 LightGBM으로 바꿨더니 0.18081가 되었고, 빈 데이터를 평균값으로 넣어줬었는데 분포가 0에 많이 몰려있는 것 같고 그게 또 유의미한거 같아서 건드리지 않았더니 0.17812가 되었다.
정규 분포를 위해서 썼던 로그때문에 많이 고생했다.
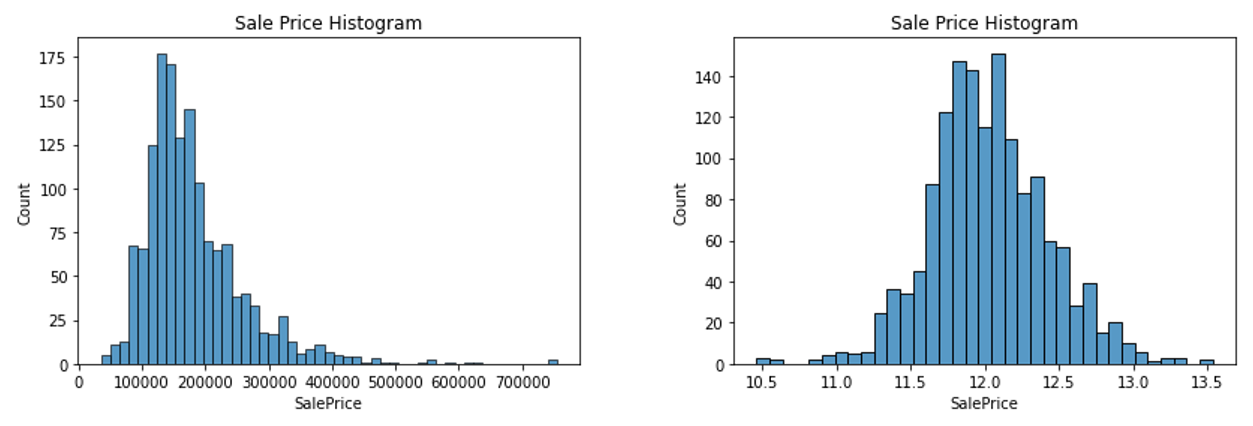
전처리는 이정도로 하고 다른 시도를 해보기로 했다.
DNN 구조로 바꾸면 성능이 나아질까 싶어서 한번 바꿔보았다.
https://www.kaggle.com/code/joonasyoon/dl-practice-on-regression?scriptVersionId=93431654
로그를 씌운 값은 그 폭이 너무 좁아서 (약 10 ~ 14), 예측값이 수렴되기에 너무 어려웠다. 그래서 DNN에서는 로그를 제거했다.
단순하게 그래프를 그려보면 정규 분포를 이루고 있지 않아서 학습이 잘 되지 않을까 걱정했는데, 상관없이 값이 잘 수렴했다. 오히려 마지막 결과 출력에 expm1 함수가 빠져서 편했다.
RMSE는 0.21882정도로, 삽질했던 ML 모델들만큼 쉽게 나왔다.
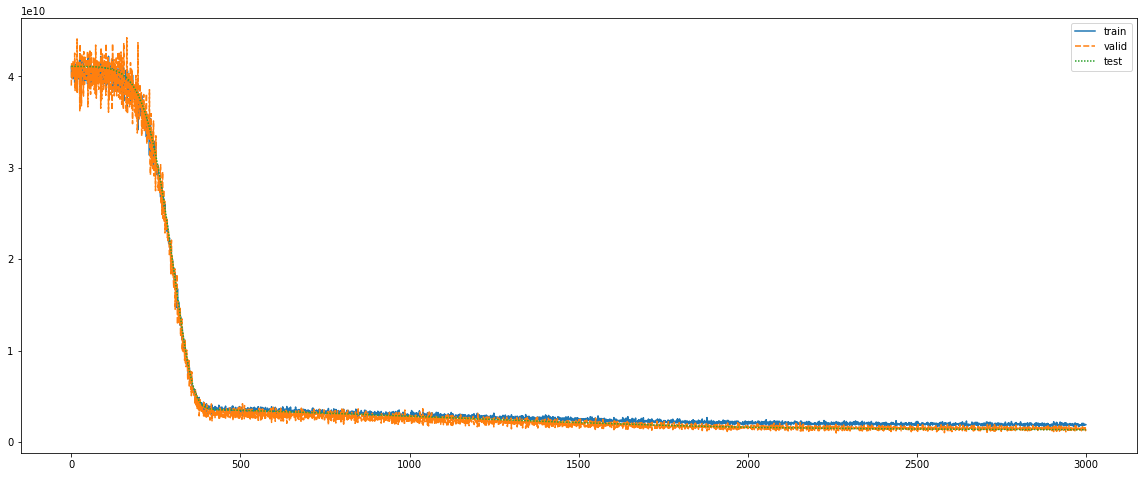
train/test 셋을 8:2로 분리하고 Fold를 3개로 나눴을 때, train set 하나에 365개의 데이터 밖에 없었다.
그래도 학습해보았고 처음에는 과적합만 되고 test loss는 쭉 커졌었는데, 어쩌다 해결되었는 지 모르겠다.
Fold 3개를 하나의 에포크로 보고 평균을 그려보면 이렇다.
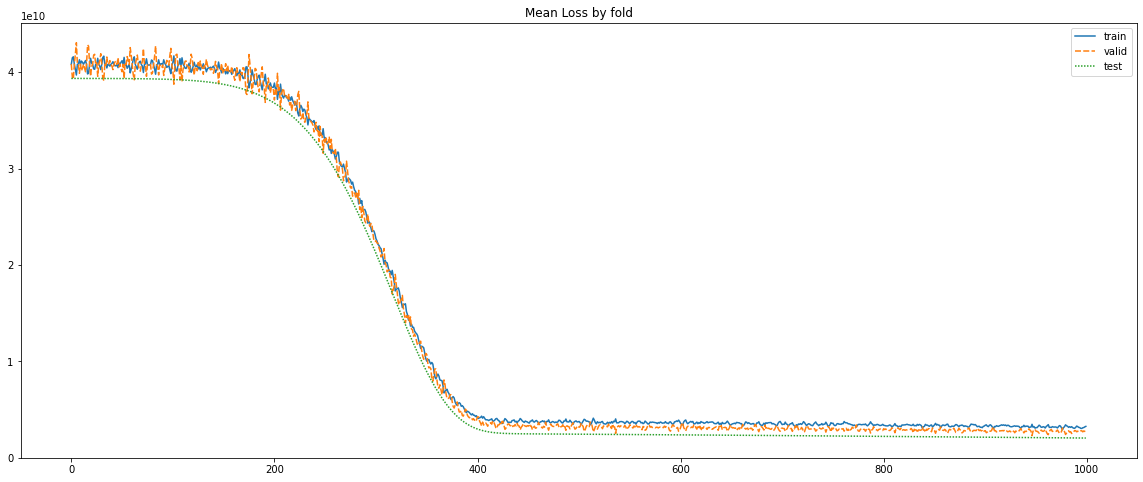
끝 부분만 확인해보면 이렇다.
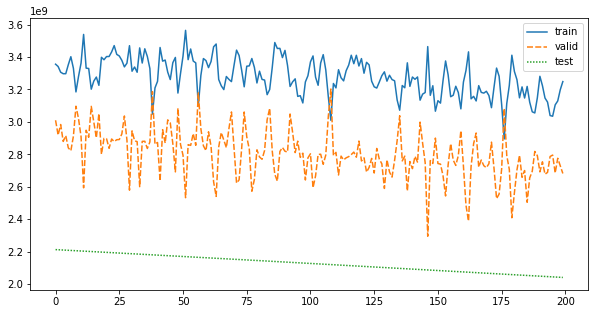
많이 들쑥날쑥 거리는데, 다음으로는 여기에 Learning rate scheduler를 적용해서 learning rate를 동적으로 조정해봐야겠다.
'AI' 카테고리의 다른 글
| [강화학습 메모] Proximal Policy Optimization (PPO, 2017) (0) | 2023.03.11 |
|---|---|
| [강화학습 메모] A3C (Asynchronous A2C, 2016) (0) | 2023.03.10 |
| [강화학습 일지] DQN Tutorial 살펴보기 (0) | 2023.01.13 |
| Loss 또는 모델 output이 NaN인 경우 확인해볼 것 (0) | 2022.04.23 |
| [PyTorch] Tensor, NumPy, Pandas 타입 표 (0) | 2022.04.19 |


