
Joonas' Note
[강화학습 메모] A3C (Asynchronous A2C, 2016) 본문
A3C (Asynchronous A2C, 2016)
- 샘플 사이의 상관 관계를 비동기 업데이트로 해결
- 리플레이 메모리를 사용하지 않음
- on-policy
개념적으로는 A2C 를 여러개 두고, 각 에이전트마다 아래와 같이 gradient를 계산해서, 그걸 글로벌 네트워크에 반영하는 방식이다.
$$ Q_{(1)}(s_t,a_t)(-\sum y_i log p_i) \rightarrow gradient_{(1)} \\ Q_{(2)}(s_t,a_t)(-\sum y_i log p_i) \rightarrow gradient_{(2)} \\ \vdots $$
배경
- A2C는 샘플 간 상관 관계에 문제가 있었다
- 시간의 흐름에 따라, 샘플을 수집했기 때문
- 또한 샘플에 따라 정책(\(\pi\))이 업데이트 되고, 업데이트 된 정책에서 샘플을 뽑기 때문에, 샘플이 동일한 분포를 가지지 못함.
- DQN은 리플레이 메모리가 필요했고, 실시간 학습(Temporal Difference)이 불가능하다.
A3C의 종류
- 그래디언트 병렬화
- 워커가 그래디언트 계산
- 데이터 병렬화
- 글로벌 신경망이 그래디언트 계산(워커는 샘플을 글로벌 신경망에 넘겨줌)
알고리즘
글로벌 신경망의 critic: \(\phi\)
액터 신경망의 파라미터: \(\theta\)
이거를 여러 개의 에이전트에 복사 \(\phi_W, \theta_w\)
워커가 3개 있다고 가정.
1번째 워커
\(\theta_w\)를 따르는 정책 \(\pi_{\theta_w}\)으로 시간 끝까지 샘플\(\left(x_i, u_i, r(x_i,u_i), x_{i+1}\right)\)을 뽑는다
워커의 n-스텝 시간차 타깃 \(y\) 계산
워커의 n-스텝 어드벤티지 \(A_{\phi_{w}}(x_i,u_i)\) 계산
워커 신경망의 그래디언트 계산
$$ \sum_{i=1}[(y_{w,i}-V_{\phi_w}(x_i))\nabla_{\phi_w}V_{\phi_w}(x_i)] $$
워커 액터 신경망의 그래디언트 계산
$$ \nabla_{\theta_w}\sum_{i}[\log(\pi_{\theta_w}(u_i\mid x_i))A_{\phi_w}(x_i,u_i)] $$
4의 값을 활용하여 글로벌 신경망 업데이트
$$ \phi\leftarrow \alpha_{critic}\sum_{i=1}[(y_{w,i}-V_{\phi_w}(x_i))\nabla_{\phi_w}V_{\phi_w}(x_i)] $$
글로벌 신경망 파라미터를 다시 워커로
데이터 병렬화는 워커에서 했던 계산들을 글로벌 신경망에서 하면 됨.
(1) Multi-step loss function
Agent가 여러개인데, 글로벌 네트워크는 하나이므로 나머지 Agent가 기다리는 상황이 생긴다.
나머지 agent는 n개의 스텝을 진행하면서, n개의 loss를 쌓고 있는다.
(2) Entrophy loss function
위 식에서 \(Q(s_t,a_t)\) 에 갑자기 뭘 곱했는데, 그게 엔트로피 식이었다.
$$ -\sum p_i log p_i $$
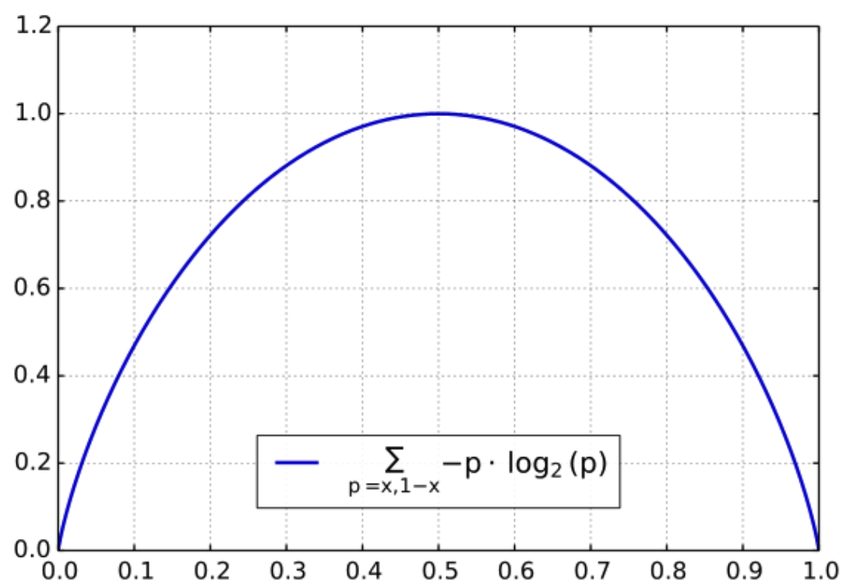
참고
'AI' 카테고리의 다른 글
| logit vs. sigmoid vs. softmax (0) | 2023.07.05 |
|---|---|
| [강화학습 메모] Proximal Policy Optimization (PPO, 2017) (0) | 2023.03.11 |
| [강화학습 일지] DQN Tutorial 살펴보기 (0) | 2023.01.13 |
| Loss 또는 모델 output이 NaN인 경우 확인해볼 것 (0) | 2022.04.23 |
| [부동산 가격 예측] LightGBM에서 DNN Regression으로 (0) | 2022.04.21 |


